磁盘 I/O
读取和写入文件 I/O 操作都需要调用操作系统的接口。因为磁盘是由操作系统来管理的,应用程序想要访问物理设备就只能通过系统调用的方式来工作
在这期间内核空间和用户空间是隔离的,所以存在数据在两处来回复制的问题
操作系统会引入缓存来加速 I/O 操作
标准访问文件方式
磁盘-高速缓存-应用程序缓存-应用程序
直接 I/O 方式
磁盘-应用程序缓存-应用程序 (例如数据库系统明确知道需要缓存、失效哪些数据)
编码相关
尽量将所有编码都设置为 UTF-8,是理想的中文编码方式
UTF-8 对单字节范围内的字符采用1个字节表示,对汉字采用3个字节表示
JVM内存分析
内存泄漏
发生内存泄露时,首先查看 Heap 的内存使用情况,查看 Major GC,Full GC 的情况,是否有对象一直没有被回收
除此之外,内存泄露还可能出现在其他需要用到内存的区域,包括 JVM 本身的 JIT 编译,JVM 栈,JNI 调用本地代码,NIO 用 Direct Buffer 申请内存等
Session 与 Cookie
Session 与 Cookie 都是为了保持用户与后端服务器的交互状态
缺点:随着 Cookie 数和访问量的增加,占用的网络带宽会增加,浏览器存储的 Cookie 也有限;Session 不容易在多台服务器之间共享
分布式 Session
有一台服务订阅服务器,为应用提供 Session 和Cookie 的配置项,精确控制哪些应用可以操作哪些 Session 和 Cookie,可以有效控制 Session 的安全性和 Cookie 的数量,简化 Cookie 的管理
应用 订阅 服务订阅服务器 使用的 Session 配置项, Session 存储到分布式缓存中
多域名的 Session 同步
需要一个跳转应用,这个应用可以被一个或者多个域名访问。这个应用从一个域名下取得 sessionID,然后将这个 sessionID 同步到另一个域名下
所以要实现多域名的 Session 同步,就要将同一个 sessionID 作为 Cookie 写到多个域名下
ClassLoader
有一个 defineClass 方法,可以将接收到的字节流解析成 JVM 能识别的 Class 对象
所以在 Java 中可以通过 1. class 文件实例化对象 2. 通过类的字节码流创建类的 Class 对象,然后进行实例化
JVM 平台的 ClassLoader 共分 3 层,BootstarpClassLoader,ExtClassLoader,AppClassLoader
其中
- BootstarpClassLoader 完全 JVM 自己控制,不能被别的类访问到。它也不是 ExtClassLoader 的父类
- ExtClassLoader 和 AppClassLoader 是 Launcher 的内部类,都继承了 URLClassLoader,URLClassLoader 实现了 ClassLoader 抽象类
- 创建 Launcher 对象会先创建 ExtClassLoader 对象,然后其作为父类加载器创建 AppClassLoader 对抗。最后由 Launcher 对象获取到的加载器是 AppClassLoader 对象
Tomcat
总体架构
- Server:Server 对应的就是一个 Tomcat 实例
- Service:一个 Service 由一个 Container 和多个 Connector 构成。Service 默认只有一个,但一个 Server 可对应多个 Service 服务。
- Connector:一个 Service 可以有多个 Connector 来实现支持多种 I/O 模型和应用层协议
- Container:一个 Container 对应多个 Connector,顶层容器其实就是 Engine
Connecter 负责对外交流,Container 负责处理 Connector 接受的请求
Connector
Connector 对 Servlet 容器屏蔽了网络协议和 I/O 模型的区别,无论是什么协议,在容器中获取到的都是一个 ServletRequest 对象
连接器需要完成 3 个高聚合功能:
- 网络通信
- 应用层协议解析
- Tomcat Request/Response 与 ServletRequest/ServletResponse 的转化
与此对应的三个组件分别为 EndPoint、Processor 和 Adapter
- Endpoint 负责底层 Socket 通信,提供字节流给 Processor
- Processor 负责应用层协议解析,提供 Tomcat Request 对象给 Adapter
- Adapter 负责调用容器,提供 ServletRequest 对象给容器
其中 Endpoint 和 Processor 一起抽象成了 ProtocolHandler,实现封装通信协议和 I/O 模型的差异
Container
加载并管理 Servlet,处理具体的 Request 请求
由 Engine、Host、Context 和 Wrapper 4个子容器组件构成,4个组件是父子关系:Engine 包含 Host,Host 包含 Context,Context 包含 Wrapper
用到的设计模式
- 组合模式管理容器(俄罗斯套娃)
- 观察者模式发布启动事件达到解耦、开闭原则
- 骨架抽象类和模版方法抽象变与不变,实现代码复用和灵活扩展
- 责任链模式(Pipeline-Valve)实现一个请求处理过程中有很多处理者一次对请求进行处理
Tomcat 的类加载器
对于 Tomcat 来说,它的类加载器是 StandardClassLoader,但它只是一个代理类,没有覆盖 loadClass() 方法,所以按照双亲委派机制,它会调用父类加载器去加载,所以加载 Tomcat 本身的依然是 AppClassLoader
Tomcat的自定义类加载器 WebappClassLoader 覆盖了 loadClass() 方法,打破了双亲委托机制,有自己的加载机制
- 先在本地 cache 查找是否加载过该类,即查看 Tomcat 的类加载器是否已经加载过这个类
- 如果 Tomcat 没有加载过这个类,就调用 findLoadedClass() 从系统类加载器的 cache 中查找是否已经加载过
- 如果都没有,尝试用 ExtClassLoader 类加载器加载。这一步目的是防止 Web 应用自己的类覆盖 JRE 的核心类,因为 ExtClassLoader 会委托给 BootstrapClassLoader 去加载
- 如果 ExtClassLoader 加载器加载失败,说明 JRE 核心类中没有该类,就在本地 Web 应用目录下查找并加载
- 如果本地目录下没有该类,说明不是 Web 应用自己定义的类,交给系统类加载器 AppClassLoader 加载
- 如果加载过程全部失败,抛出 ClassNotFound 异常
Servlet
在 Tomcat 的容器等级中,由 Context 容器直接管理 Servlet 在容器中的包装类 Wrapper

为什么要将 Servlet 包装成 StandardWrapper 而不包装成 Servlet 对象?
- 为了不将 Servlet 强耦合在Tomcat中。StandardWrapper 是 Tomcat 容器的一部分,具有容器的特征。
Servlet 体系结构
Servlet 中主要包含四个类,其中
- ServletConfig 获取 Servlet 的一些配置属性
- ServletContext 负责描述 Servlet 运行的交易场景,这个交易场景是用来让两个模块进行数据交换
- ServletRequest 和 ServletResponse 是交互的具体对象
Servlet 工作方式
用户从浏览器发出一个请求,其中带有 hostname port 和 URL
hostname port 用来建立 TCP 连接,服务器根据 URL 来到达正确的 Servlet 容器
这个映射关系由 Mapper 组件来完成,这个类保存了 Tomcat 的 Container 中所有子容器的信息。在 Request 类进入 Container 之前,mapper 就已经确定了它要访问的子容器 (有一个 MapperListener 类会作为监听者被添加到 Container 的所有子容器中,容器的变化会反应到对应 MapperListener 的 mapper 属性的修改中)
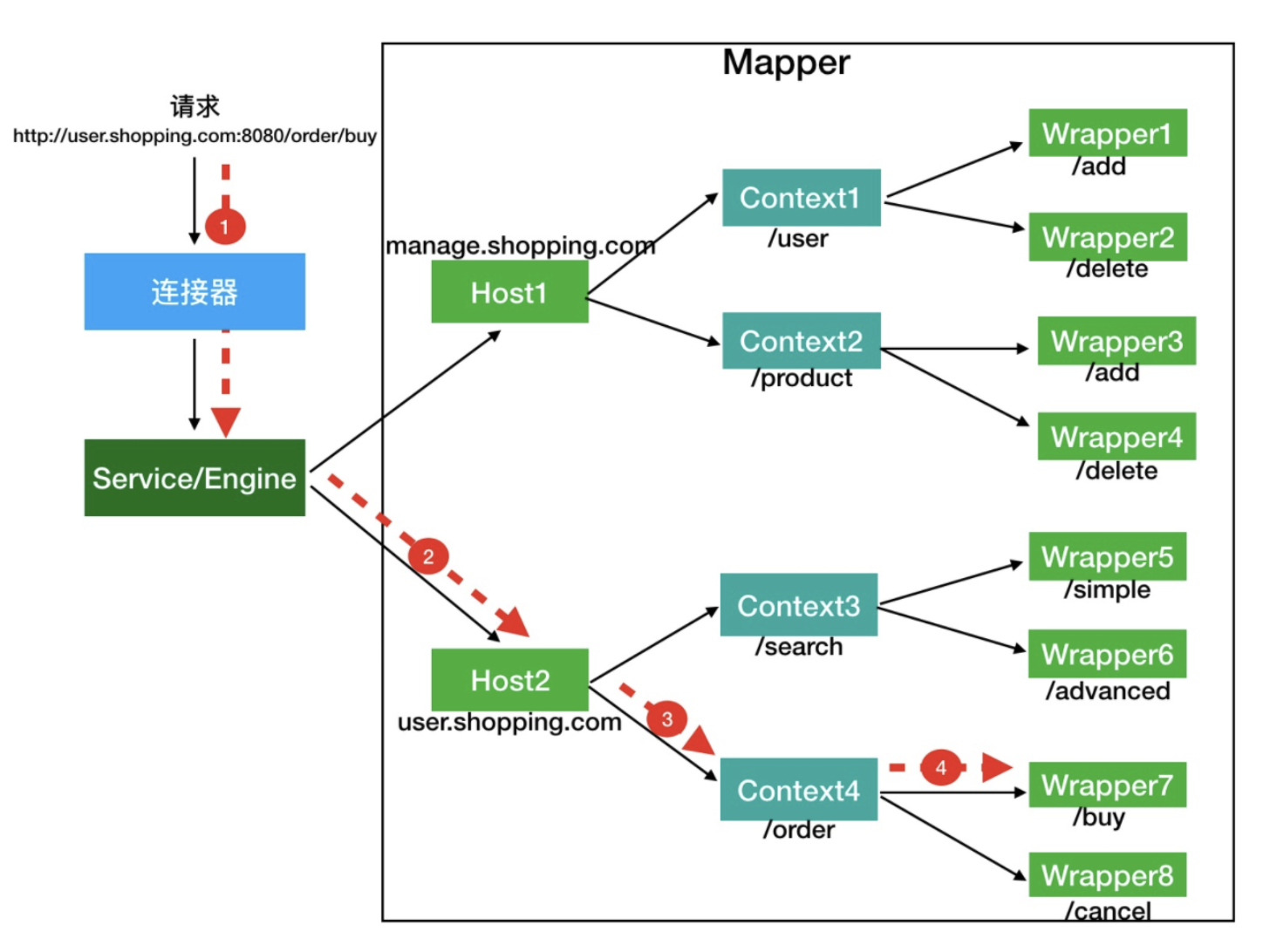
容器的先后顺序为:Engine -> Host -> Context -> Wrapper 找到对应的 Servlet 后执行 Servlet 的 service 方法
**门面设计模式**
Servlet 中的 StandardWrapperFacade、ApplicationContextFacade 都是门面对象。门面设计模式起到对数据的封装作用,别的系统通过这个门面来访问数据。
Spring
三大核心组件是 Bean、Core 和 Context
- Bean 包装的是 Object 对象,这些对象的依赖关系由 IoC 容器来统一管理
- Context 本身是 Bean 之间关系的集合,充当 IoC 容器的角色。Bean 之间的关系主要是依赖注入的注入关系
- Core 是发现、建立和维护 Bean 之间关系所需要的一系列工具
参考
Tomcat 架构原理解析到架构设计借鉴